Ripper Web Content | Capture Metadata ContentRipper Nội dung Web | Chụp Nội dung Siêu dữ liệu
Ripper Web Content là một tiện ích mở rộng Chrome linh hoạt cho phép người dùng phân tích và trích xuất dữ liệu metadata từ nội dung trên web. Được phát triển bởi Miguel Segovia, công cụ miễn phí này là một tài sản quý giá trong lĩnh vực pháp y kỹ thuật số, môi trường điều tra và lĩnh vực Tình báo Nguồn mở (OSINT).
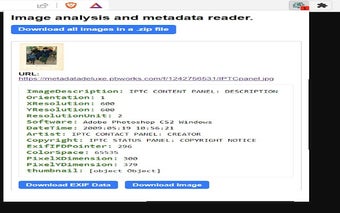
Với Ripper Web Content, người dùng có thể thu thập và tải xuống metadata hình ảnh, làm cho nó trở thành một công cụ cần thiết để phân tích hình ảnh trong nhiều ngữ cảnh khác nhau. Tiện ích mở rộng cũng cung cấp khả năng tìm kiếm hình ảnh ngược bằng cách sử dụng Google Lens và TinEye, cho phép người dùng tìm ra nguồn gốc ban đầu của một hình ảnh hoặc tìm kiếm các hình ảnh tương tự trực tuyến.
Một trong những tính năng nổi bật của Ripper Web Content là tích hợp với FotoForensics. Điều này cho phép người dùng phân tích hình ảnh để xác định bất kỳ sự can thiệp hoặc sửa đổi nào, làm cho nó trở thành một công cụ hữu ích để xác minh tính xác thực của hình ảnh trong công việc điều tra.
Tiện ích mở rộng cũng cung cấp khả năng phát hiện khuôn mặt, cung cấp thông tin như số người trong một bức ảnh, giới tính, tuổi tác và tâm trạng của họ. Tính năng này có thể hữu ích đặc biệt trong việc xác định cá nhân hoặc thu thập thông tin từ biểu hiện khuôn mặt.
Ngoài việc phân tích hình ảnh, Ripper Web Content cho phép người dùng quét và trích xuất metadata từ các định dạng tài liệu khác nhau như PDF, DOCX, PPTX và XLSX. Tính năng này cho phép người dùng thu thập thông tin từ các tài liệu trên web một cách nhanh chóng và hiệu quả.
Tổng thể, Ripper Web Content là một công cụ mạnh mẽ và toàn diện để phân tích và trích xuất metadata từ nội dung web. Sự đa dạng tính năng của nó làm cho nó trở thành một tài sản vô giá cho pháp y kỹ thuật số, điều tra và công việc OSINT.